거래소로부터 데이터 불러오기
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
import ccxt,pandas as pd
import datetime
def to_timestemp(dt):
dt = datetime.datetime.timestamp(dt)
dt = int(dt) * 1000
return dt
binance = ccxt.binance()
col = ['datetime', 'open', 'high', 'low', 'close', 'volume']
format = '%Y-%m-%d %H:%M:%S'
dt = datetime.datetime.strptime('2018-01-01 00:00:00',format)
dt = to_timestemp(dt)
btc_ohlcv = binance.fetch_ohlcv("BTC/USDT",limit = 1000,timeframe="1d",since=dt)
df = pd.DataFrame(btc_ohlcv,columns=col)
df['datetime'] = pd.to_datetime(df['datetime'], unit='ms')
df.set_index('datetime', inplace=True)
|
cs |
ccxt 라이브러리를 사용하여 바이낸스의 비트코인 데이터를 2018-01-01 이후로부터 1000개의 데이터를 받아왔다.
보조지표 추가
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
|
import pandas_ta as pta, pandas as pd, numpy as np
def add_rsi(entire_df,data_name = 'close',period = 14):
rsi = pta.rsi(entire_df[data_name], length=period)
entire_df['rsi'+'_'+str(period)] = rsi
return entire_df
def add_ma(entire_df, data_name = 'close',period = 20):
entire_df['mean'+'_'+str(period)] = entire_df[data_name].rolling(window=period).mean()
return entire_df
def add_ema(df, period: int = 30):
array = df['close']
ema = pta.ma("ema", pd.Series(array.astype(float)), length=int(period))
df['ema'+'_'+str(period)] = ema
return df
def add_stochastic(df,n = 14,m = 5,t = 5):
ndays_high = df.high.rolling(window = n,min_periods = 1).max()
ndays_low = df.low.rolling(window = n,min_periods = 1).min()
fast_k = ((df.close - ndays_low) / (ndays_high - ndays_low)) * 100
slow_k = fast_k.ewm(span=t).mean()
slow_d = slow_k.ewm(span=t).mean()
df = df.assign(fast_k = fast_k, fast_d = slow_k, slow_k = slow_k, slow_d = slow_d)
return df
def add_bb(df,length = 20,std = 2):
currunt_close = df["close"]
currunt_upper_bollinger_band = pta.bbands(df["close"], length = length, std = std)
df = df.assign(BBL = currunt_upper_bollinger_band['BBL_'+str(length)+'_2.0'],BBM = currunt_upper_bollinger_band['BBL_'+str(length)+'_2.0'],
BBU = currunt_upper_bollinger_band['BBL_'+str(length)+'_2.0'],BBP = currunt_upper_bollinger_band['BBL_'+str(length)+'_2.0'])
return df
def add_disparity(df,period = 20):
# 종가기준으로 이동평균선 값을 구함
ma = df["close"].rolling(period).mean()
# 시가가 이평선 기준으로 얼마나 위에 있는지 구함
df['disparity'] = 100*(df["open"]/ma)
return df
df = add_rsi(df)
df = add_ma(df)
df = add_ema(df)
df = add_bb(df)
df = add_stochastic(df)
df = add_disparity(df)
df
|
cs |
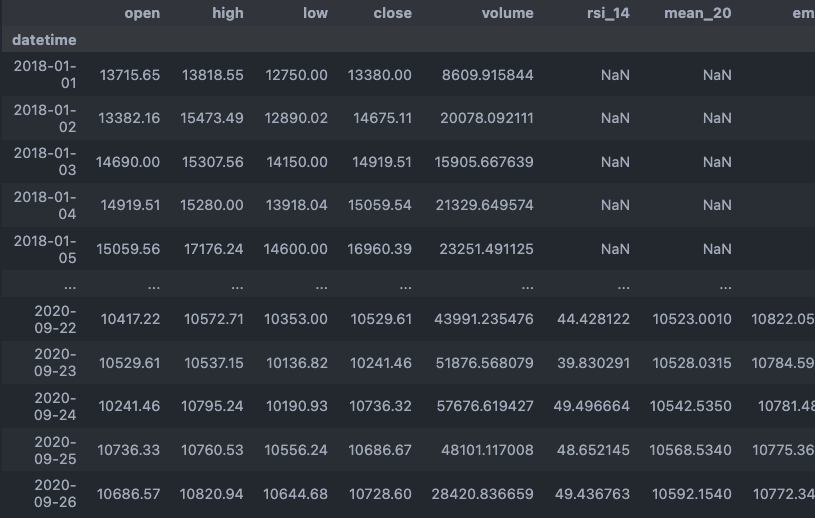
pandas_ta 라이브러리를 사용하여 rsi, ma, ema, stochastic, bolingerband, disparity 지표를 데이터에 추가해 주었다. pandas_ta의 사용법은 pandas_ta 깃허브를 찾아보면 된다.
https://github.com/twopirllc/pandas-ta
GitHub - twopirllc/pandas-ta: Technical Analysis Indicators - Pandas TA is an easy to use Python 3 Pandas Extension with 130+ In
Technical Analysis Indicators - Pandas TA is an easy to use Python 3 Pandas Extension with 130+ Indicators - GitHub - twopirllc/pandas-ta: Technical Analysis Indicators - Pandas TA is an easy to us...
github.com
데이터 스케일링
|
1
2
3
4
5
6
7
8
9
10
|
scaling_col = ['mean_20','ema_30','BBL','BBM','BBU','BBP']
for i in scaling_col:
temp = []
temp.append(df.iloc[0][i]/df.iloc[0]['close'])
for j in range(1, len(df)):
value = ((df.iloc[j][i] + 0.0001) / df.iloc[j-1]['close'])
temp.append(value)
df[i] = temp
df = df.dropna()
df
|
cs |
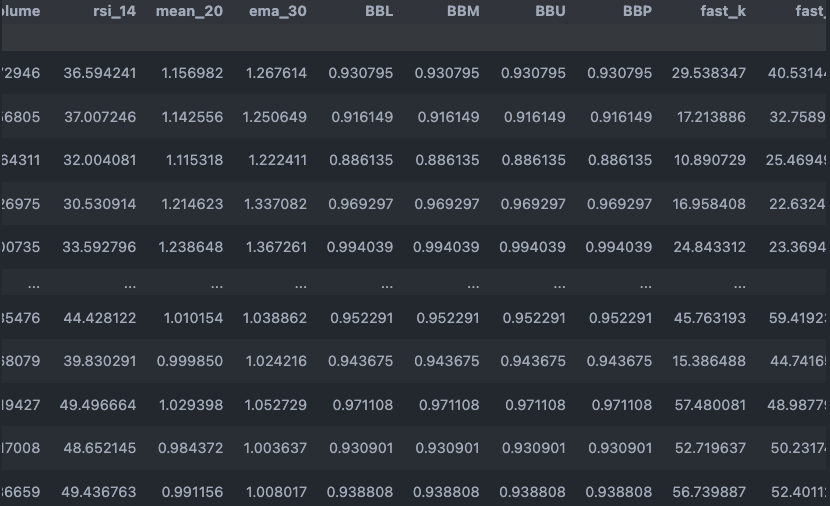
대부분의 지표값이 큰 차이가 없이 잘 표준화 된 것 같다.
데이터 3차원으로 만들기
RNN은 3차원 데이터만 입력으로 받기 때문에 현재 2차원 데이터를 3차원을 바꾸어줘야한다. 그래서 20개씩 묶어서 다음날의 종가를 예측하도록 데이터를 구성하였다.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
|
def MakeDataset(data,label,window_size = 10):
x,y = [],[]
for i in range(len(data) - window_size):
x.append(data.iloc[i:i+window_size])
y.append(label.iloc[i+window_size])
return np.array(x),np.array(y)
feature_data = df.drop(['close'],axis = 1)
label_data = df.close
x,y = MakeDataset(feature_data,label_data,window_size=20)
x_train = x[:800]
y_train = y[:800]
x_test = x[800:]
y_test = y[800:]
|
cs |
데이터를 3차원으로 만들어준 후 훈련데이터와 테스트 데이터를 나누어 주었다.
예측 모델 생성
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
import numpy as np
import tensorflow as tf
import matplotlib.pyplot as plt
from keras.layers import SimpleRNN,Dense
from keras.models import Sequential
model = Sequential()
model.add(SimpleRNN(64,
input_shape = (x_train.shape[1],x_train.shape[2]),
activation = "relu"
))
model.add(Dense(32))
model.add(Dense(16))
model.add(Dense(8))
model.add(Dense(1))
model.compile(loss="mse",optimizer="adam")
|
cs |
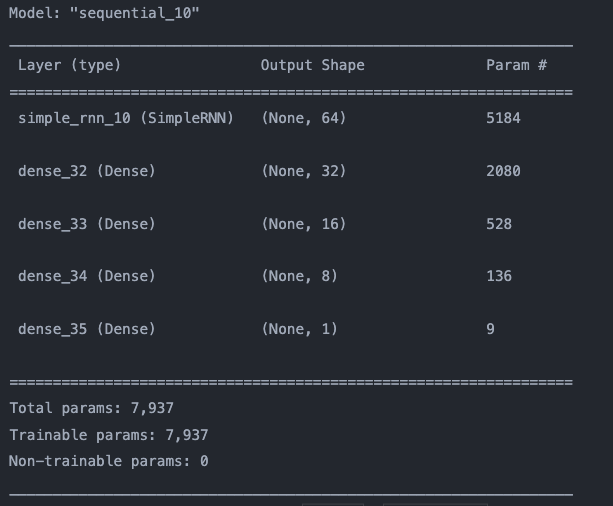
SimpleRNN을 사용하여서 모델을 구성하였고 손실함수는 평균제곱함수, 옵티마이저는 adam을 사용하였다.
출력은 다음날의 종가하나이므로 하나로 지정해주었다.
모델 훈련 및 평가
|
1
2
3
4
5
6
7
8
9
|
model.fit(x_train,y_train,epochs=100,batch_size=16)
import matplotlib.pyplot as plt
from sklearn.metrics import mean_squared_error
pred = model.predict(x_test)
print(mean_squared_error(pred,y_test))
fig = plt.figure(figsize=(16,9))
fig = plt.plot(pred,label = "pred")
fig = plt.plot(y_test,label = "real")
fig = plt.legend()
|
cs |
epochs는 100으로 주었고 배치사이즈는 32로 했었으나 정확도가 현저히 떨어져서 16으로 하고 훈련을 시켰다. 그리고 예측한 값과 실제 값을 그래프로 비교해 보았다.
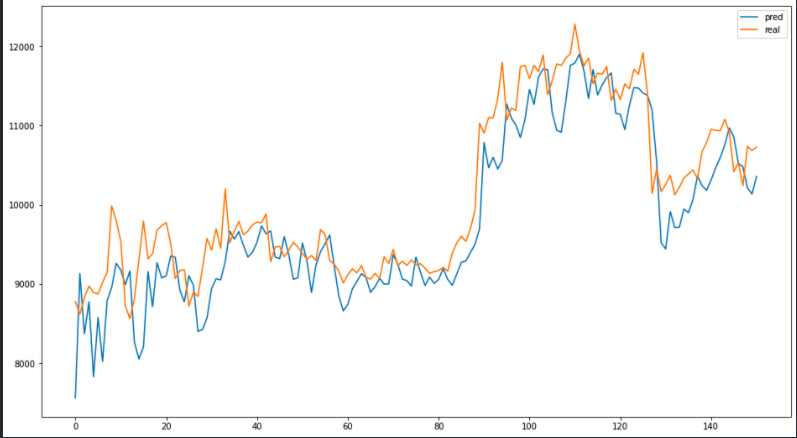
RNN의 문제인 장기 의존성 문제점 (Long-Term Dependency Problem)이 있기 때문에 좋은 성능은 내지 못했지만 어느정도 추세정도는 따라 가는 것을 볼 수 있다. LSTM이 장기 의존성 문제점을 해결 할 수 있으므로 LSTM 모델로 바꿔서 해야겠다는 생각이 들었다.
'파이썬 머신러닝' 카테고리의 다른 글
| [ML/AI][Bitcoin Trend Prediction with ML/머신러닝 활용한 비트코인 추세예측] (1) | 2022.09.26 |
|---|---|
| [ML/AI][SimpleRNN with Keras] (2) | 2022.09.20 |
| [머신러닝][교차검증, 파라미터 튜닝] (0) | 2021.05.02 |
| [머신러닝][kaggle 실습- 보험 비용 예측하기] (2) | 2021.02.23 |
| [머신러닝][Deep learning을 이용한 XOR문제해결] (0) | 2021.02.14 |