서론
기존의 주가예측은 가격 데이터 및 거시경제 데이터를 기반으로 다음날의 종가를 RNN, LSTM 같은 순환 신경망 모델로 예측하였다. 여러 논문의 예측 결과 그래프를 보면 거짓말같이 실제 주가와 거의 비슷하게 예측되는 결과물이 많이 있다. 하지만 자세히 보면 예측한 그래프가 원래 그래프 보다 1일 앞에 있는것과 비슷하다는 것을 알 수 있다. 이러한 이유는 모델이 학습을 할때 loss값이 현재 값- 전날 값이 가장 최적의 loss값이라고 판단했기 때문에 이러한 결과가 나오는 것이다. 그리고 다음날의 종가는 거의 랜덤한 값의 가깝기 때문에 정확하게 예측하는 것은 한계가 있다. 이러한 한계가 있기 때문에 주가 추세 예측에 대한 연구를 하게 되었다.
예측 모델로는 classification 모델인 LinearRegression, xgboost 모델을 사용하고 추세 역시 과거의 데이터의 영향을 받기 때문에 순환 신경망 모델인 LSTM을 사용해서도 예측해 보겠다. 데이터로는 바이낸스 거래소의 BTC/USDT의 1d,1h,4h봉의 데이터의 추세를 라벨링을 한 후에 테스트 데이터와 학습데이터를 나누어서 모델을학습하고 테스트 데이터와 예측 데이터를 분석하였다.
추세 라벨링 알고리즘
- 고점
- 다음 봉의 종가가 max(전저점 ~ 커서값) 의 값보다 크면 앞으로 선행조사범위(lookahead range: ,사용자 지정)일 동안의 더 큰 값이 있는지 체크한다.
- 없으면 그 값은 앞으로 term일 전까지 고점이므로 저장
- 있으면 max의 값만 업데이트 해준다.
- 저점
- 다음 봉의 종가가 min(전고점 ~ 커서값) 의 값보다 크면 앞으로 선행조사범위(lookahead range: ,사용자 지정)일 동안의 더 작은 값이 있는지 체크한다.
- 없으면 그 값은 앞으로 term일 전까지 저점이므로 저장
- 있으면 min의 값만 업데이트 해준다.
- 첫 일정구간동안 max/min을 저점/고점으로 지정하고, 시작하는 알고리즘
- 시작일(사용자가 지정한 데이터 날짜) ~ 시작일 + previous_range 구간중의 제일 작은 값을 previous_min, 제일 큰 값을 previous_max라고 할 때 previous_min ,previous_max의 중에 더 늦은 시점에 나온 값을 Last_label 이라고 하자.
- Last_label의 경우는 2가지 이다.
- max가 Last_label인 경우
- previous_max값의 시점을 t라고 할 때 (t + lookahead range]의 구간에서 더 큰 값이 있는 경우 Last_label은 previous_min이 된다.
- previous_max값의 시점을 t라고 할 때 (t + lookahead range]의 구간에서 더 큰 값이 없는 경우 Last_label은 previous_max가 된다.
- previous_min이 Last_label인 경우
- previous_min값의 시점을 t라고 할 때 (t + lookahead range]의 구간에서 더 작은 값이 있는 경우 Last_label은 previous_max가 된다.
- previous_min값의 시점을 t라고 할 때 (t + lookahead range]의 구간에서 더 작은 값이 없는 경우 Last_label은 previous_min이 된다.
- max가 Last_label인 경우
- Last_label이 previous_max인 경우 previous_max의 시점에서 부터 저점 알고리즘을 먼저 실행한다.
- Last_label이 previous_min인 경우 previous_min의 시점에서 부터 고점 알고리즘을 먼저 실행한다.
고점과 저점을 구한 상태에서 두점을 이어서 저점에서 고점을 이은 구간을 상승추세라하고 고점에서 저점을 이은 구간을 하락추세라고 라벨링하였다.

빨간색은 상승추세, 파란색은 하락추세이다.
인풋 데이터를 어떤 것을 줄 것인가?
- 주식가격 데이터
- 보조지표(ma, rsi, macd, stocastic…)
- 전전날과 전날의 상승폭 또는 하락폭
- 코스피지수가 현재 상승인지 하락인지
해당 글에서는 1,2번의 데이터만을 사용하여 분석하였다.
데이터를 스케일링 하는 방법
- min/max scaling 사용하여 각각의 칼럼을 스케일링
- 각각의 칼럼을 전날의 종가로 나누어서 스케일링
- 전날의 종가로 나누는 이유는 볼린저밴드나 이동평균선은 해당 날짜의 가격을 가지고 구하기 때문에 전체 데이터에 대해서 상대적이지 않을 수 있다. 특정 일자에 편향될 수 있다.
해당 글에서는 2번의 방법을 선택했다.
코드
데이터 수집
바이낸스 거래소 API를 사용해서 BTC/USDT 데이터를 2018-02-19 ~ 2022-09-26까지의 일봉 데이터를 수집하였다. 수집한 데이터를 pandas_ta 라이브러리를 사용하여 필요한 지표를 추가하였다. 코드는 다음과 같다.
DATA_INDICATORS.py
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
|
import pandas_ta as pta, pandas as pd, numpy as np
from dataread import download_data
def add_rsi(entire_df,data_name = 'close',period = 14):
rsi = pta.rsi(entire_df[data_name], length=period)
entire_df['rsi'+'_'+str(period)] = rsi
return entire_df
def add_ma(entire_df, data_name = 'close',period = 20):
entire_df['mean'+'_'+str(period)] = entire_df[data_name].rolling(window=period).mean()
return entire_df
def add_ema(df, period: int = 30):
array = df['close']
ema = pta.ma("ema", pd.Series(array.astype(float)), length=int(period))
df['ema'+'_'+str(period)] = ema
return df
def add_stochastic(df,n = 14,m = 5,t = 5):
ndays_high = df.high.rolling(window = n,min_periods = 1).max()
ndays_low = df.low.rolling(window = n,min_periods = 1).min()
fast_k = ((df.close - ndays_low) / (ndays_high - ndays_low)) * 100
slow_k = fast_k.ewm(span=t).mean()
slow_d = slow_k.ewm(span=t).mean()
df = df.assign(fast_k = fast_k, fast_d = slow_k, slow_k = slow_k, slow_d = slow_d)
return df
def add_bb(df,length = 20,std = 2):
currunt_close = df["close"]
currunt_upper_bollinger_band = pta.bbands(df["close"], length = length, std = std)
df = df.assign(BBL = currunt_upper_bollinger_band['BBL_'+str(length)+'_2.0'],BBM = currunt_upper_bollinger_band['BBL_'+str(length)+'_2.0'],
BBU = currunt_upper_bollinger_band['BBL_'+str(length)+'_2.0'],BBP = currunt_upper_bollinger_band['BBL_'+str(length)+'_2.0'])
return df
def add_macd(
df: np.ndarray,
fast_period: int = 12,
slow_period: int = 26,
):
temp = pta.macd(
pd.Series(np.array(df['close']).astype(float)),
fast=int(fast_period),
slow=int(slow_period),
signal=9,
)
print(temp)
macd = temp[temp.columns[0]]
df['macd'+'_'+str(fast_period)+'_'+str(slow_period)] = macd
return df
def add_disparity(df,period = 20):
# 종가기준으로 이동평균선 값을 구함
ma = df["close"].rolling(period).mean()
# 시가가 이평선 기준으로 얼마나 위에 있는지 구함
df['disparity'] = 100*(df["open"]/ma)
return df
# df = download_data(since = '2020-01-01 00:00:00').get_data()
# entire_df = add_macd(df,fast_period=8,slow_period=21)
# print(entire_df)
|
cs |
DataLabeling.ipnb
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
205
206
207
208
209
210
211
212
213
214
215
216
217
218
219
220
221
222
223
224
225
226
227
228
229
230
231
232
233
234
235
236
237
238
239
240
241
242
243
244
245
246
247
248
249
250
251
252
253
254
255
256
257
258
259
260
261
262
263
264
265
266
267
268
269
270
271
272
273
274
275
276
277
278
279
280
281
282
283
284
285
286
287
288
289
290
291
292
293
294
295
296
297
298
299
300
|
import ccxt
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
import numpy as np
import datetime as datetime
import FinanceDataReader as fdr
import math
from DATA_INDICATORS import *
from dataread import download_data
from sklearn.model_selection import train_test_split
from sklearn.metrics import classification_report
class download_data:
def __init__(self,data_type = "coin",stock_code = "131100",stock_start = '2010-01-01',stock_end = '2022-01-0',since='2018-01-01 00:00:00',
code_name = 'BTC/USDT',frame = '1d',limit=10,data_amount = 1000):
self.data_type = data_type
self.stock_code = stock_code
self.stock_start = stock_start
self.stock_end = stock_end
self.since = since
self.code_name = code_name
self.frame = frame
self.limit = limit
self.data_amount = data_amount
def FinanceData(self):
df = fdr.DataReader(str(self.code), self.stock_start, self.stock_end)
df = df.drop(['Change'],axis = 1)
col = [i.lower() for i in df.columns.to_list()]
df.columns = col
return df
def to_timestemp(self,dt):
dt = datetime.datetime.timestamp(dt)
dt = int(dt) * 1000
return dt
def set_df(self,dt):
binance = ccxt.binance()
col = ['datetime', 'open', 'high', 'low', 'close', 'volume']
btc_ohlcv = binance.fetch_ohlcv(self.code_name,limit = self.data_amount,timeframe=self.frame,since=dt)
df = pd.DataFrame(btc_ohlcv,columns=col)
df['datetime'] = pd.to_datetime(df['datetime'], unit='ms')
df.set_index('datetime', inplace=True)
return df
def concat_data(self):
format = '%Y-%m-%d %H:%M:%S'
dt = datetime.datetime.strptime(self.since,format)
dt = self.to_timestemp(dt)
df = self.set_df(dt)
data = df
for i in range(self.limit):
dt = self.to_timestemp(df.index[-1])
df = self.set_df(dt)
data = pd.concat([data,df])
return data
def down_data(self):
if self.data_type == "coin":
return self.concat_data()
elif self.data_type == "stock":
return self.FinanceData()
class DataLaeling(download_data):
def __init__(self,lookahead_range,MinMaxGap,target_price = "close",since='2018-01-01 00:00:00',code_name = 'BTC/USDT',frame = '1d',limit=10,data_amount = 1000,ma_window = 14,alpha = 0.1,gap = 1):
self.lookahead_range = lookahead_range
self.MinMaxGap = MinMaxGap
self.since = since
self.code_name = code_name
self.frame = frame
self.limit = limit
self.data_amount = data_amount
self.target_price = target_price
self.ma_window = ma_window
self.alpah = alpha
self.gap = gap
super().__init__(since = self.since, code_name = self.code_name, frame = self.frame, limit = self.limit, data_amount = self.data_amount)
self.data = self.down_data()
def transpose(self,high_range,low_range):
temp = []
for z in range(len(self.data)):
cnt = 0
# 고점
for i in high_range:
for j in i:
if self.data.index[z] == j:
temp.append(1)
cnt = 1
break
if cnt != 0:
continue
# 저점
else:
for i in low_range:
for j in i:
if self.data.index[z] == j:
temp.append(-1)
cnt = 1
break
if cnt != 0:
continue
# 고점, 저점 아닌 점
else:
temp.append(0)
self.data['label'] = temp
def find_max(self,idx):
for i in range(idx+1,idx + self.lookahead_range + 1):
if self.data[self.target_price][i] > self.data[self.target_price][idx]:
return False
return True
def find_min(self,idx):
for i in range(idx+1,idx + self.lookahead_range + 1):
if self.data[self.target_price][i] < self.data[self.target_price][idx]:
return False
return True
def StartSearching(self):
max_index = self.data[self.data[self.target_price] == max(self.data[self.target_price][:self.lookahead_range])].index[0]
min_index = self.data[self.data[self.target_price] == min(self.data[self.target_price][:self.lookahead_range])].index[0]
max_num = [i for i in range(len(self.data)) if max_index == self.data.index[i]][0]
min_num = [i for i in range(len(self.data)) if min_index == self.data.index[i]][0]
if max_index > min_index:
Last_label = max_index
ck,start = 1,max_num
if not self.find_max(max_num):
Last_label = min_index
ck,start = 0,min_num
elif min_index > max_index:
Last_label = min_index
ck,start = 0,min_num
if not self.find_min(min_num):
Last_label = max_index
ck,start = 1,max_num
return Last_label,ck,start
def find_mid_point(self,start,end,target):
result = 999999999
idx = 0
for i in range(start,end + 1):
if abs(target - self.data.iloc[i][self.target_price]) < result:
result = abs(target - self.data.iloc[i][self.target_price])
idx = i
return idx
def draw_label(self):
df = self.data
fig = plt.figure(figsize=(25,13))
fig = plt.plot(df.close,color='g')
line = []
ma = self.data[self.target_price].rolling(window=self.ma_window).mean()
for i in range(0,self.ma_window):
ma[i] = self.data[self.target_price][i]
for i in range(len(df)):
line2 = []
if df.label[i] == 1:
fig = plt.scatter(df.index[i],df.iloc[i]['close'],color='r')
# fig = plt.annotate(df.index[i], xy = (df.index[i+1], df.iloc[i]['close']-1000))
line2.append(df.index[i])
line2.append(df.iloc[i]['close'])
line2.append(ma[i])
line2.append(i)
line.append(line2)
elif df.label[i] == -1:
fig = plt.scatter(df.index[i],df.iloc[i]['close'],color='b')
# fig = plt.annotate(df.index[i], xy = (df.index[i+1], df.iloc[i]['close']-1000))
line2.append(df.index[i])
line2.append(df.iloc[i]['close'])
line2.append(ma[i])
line2.append(i)
line.append(line2)
# fig = plt.plot(ma)
# 상승 : red
# 하락 : blue
# 횡보 : gray
entire_mean_volume = self.data['volume'].mean()
temp = [0 for i in range(len(self.data))]
diagonal_mean = []
for i in range(0,len(line)-1,1):
height = abs(self.data.iloc[line[i][3]][self.target_price] - self.data.iloc[line[i+1][3]][self.target_price])
width = abs(line[i][3] - line[i+1][3])
diagonal = math.sqrt(height**2 + width**2)
test = math.asin(width/diagonal)
diagonal_mean.append(test)
diagonal_mean.sort()
M = int(len(diagonal_mean) * 7/10)
for i in range(0,len(line)-1,1):
mid = (line[i + 1][1] + line[i][1])/2
ret = self.find_mid_point(line[i][3],line[i+1][3],mid)
temp_mean_volume = self.data.iloc[line[i][3]:line[i+1][3] + 1]['volume'].mean()
height = abs(self.data.iloc[line[i][3]][self.target_price] - self.data.iloc[line[i+1][3]][self.target_price])
width = abs(line[i][3] - line[i+1][3])
diagonal = math.sqrt(height**2 + width**2)
test = math.asin(width/diagonal)
# print(test)
# 상승 구간
if line[i][1] < line[i + 1][1] and test < M:
fig = plt.plot([line[i][0],line[i+1][0]], [line[i][1],line[i+1][1]],color='red',alpha = 0.5)
temp[line[i][3]:line[i+1][3]] = [0 for i in range(line[i+1][3] - line[i][3])]
pass
# 하락 구간
elif line[i][1] > line[i + 1][1] and test < M:
fig = plt.plot([line[i][0],line[i+1][0]], [line[i][1],line[i+1][1]],color='blue', alpha = 0.5)
temp[line[i][3]:line[i+1][3]] = [1 for i in range(line[i+1][3] - line[i][3])]
pass
# 횡보 구간
else:
fig = plt.plot([line[i][0],line[i+1][0]], [line[i][1],line[i+1][1]],color='black')
temp[line[i][3]:line[i+1][3]] = [2 for i in range(line[i+1][3] - line[i][3])]
self.data['label'] = temp
self.data = self.data.iloc[line[0][3]:line[-1][3]]
fig = plt.savefig("Labeling_" + str(self.code_name).replace('/','_') +".png")
def labeing(self):
Last_label, ck, start_index = self.StartSearching()
temp_line = []
high_label = []
low_label = []
if ck == 0:
temp_line.append(start_index-1)
temp_line.append(self.data.index[start_index-1])
low_label.append(temp_line)
max = self.data[self.target_price][start_index-1]
previous_min = self.data[self.target_price][start_index-1]
min = 999999999
else:
temp_line.append(start_index-1)
temp_line.append(self.data.index[start_index-1])
high_label.append(temp_line)
previous_max = self.data[self.target_price][start_index-1]
min_index = [start_index-1]
min = self.data[self.target_price][start_index-1]
max = 0
temp_index = 0
for i in range(start_index,len(self.data)-self.lookahead_range):
line = []
if ck == 0: # 고점을 찾는다
if self.data[self.target_price][i] > max and self.data[self.target_price][i] >= previous_min: # 만약 현재 인덱스 값이 max보다 클시
if self.find_max(i): # 만약에 앞에 term일 동안 더 큰 값이 없으면 고점이라고 판단
line.append(i)
line.append(self.data.index[i])
high_label.append(line)
previous_max = self.data[self.target_price][i]
max = 0
ck = 1
temp_index = i
elif not self.find_max(i): # 만약 앞에 term일 동안 더 큰 값이 있으면 고점이 아님 , max값만 업데이트
max = self.data[self.target_price][i]
elif ck == 1: # 저점을 찾는다.
if self.data[self.target_price][i] < min and self.data[self.target_price][i] <= previous_max:
if self.find_min(i):
line.append(i)
line.append(self.data.index[i])
low_label.append(line)
previous_min = self.data[self.target_price][i]
min = 999999999
ck = 0
temp_index = i
elif not self.find_min(i):
min = self.data[self.target_price][i]
last_index = -1
for i in range(temp_index,len(self.data)):
if self.data[self.target_price][i] == max:
last_index = i
elif self.data[self.target_price][i] == min:
last_index = i
elif self.data[self.target_price][i] > max and ck == 0:
last_index = i
max = self.data[self.target_price][i]
elif self.data[self.target_price][i] < min and ck == 1:
last_index = i
min = self.data[self.target_price][i]
if ck == 0:
line.append(last_index)
line.append(self.data.index[last_index])
high_label.append(line)
else:
line.append(last_index)
line.append(self.data.index[last_index])
low_label.append(line)
self.transpose(high_label,low_label)
class1 = DataLaeling(60,20,since = "2010-01-01 00:00:00",code_name = "BTC/USDT",frame='1d',limit=20)
class1.labeing()
class1.draw_label()
df = class1.data
df = add_rsi(df)
df = add_ma(df)
df = add_ema(df)
df = add_ma(df,period=60)
df = add_ema(df,period=60)
df = add_stochastic(df)
df = add_bb(df,length=60)
df = add_disparity(df,period=60)
df = df.dropna()
df.tail(5)
|
cs |
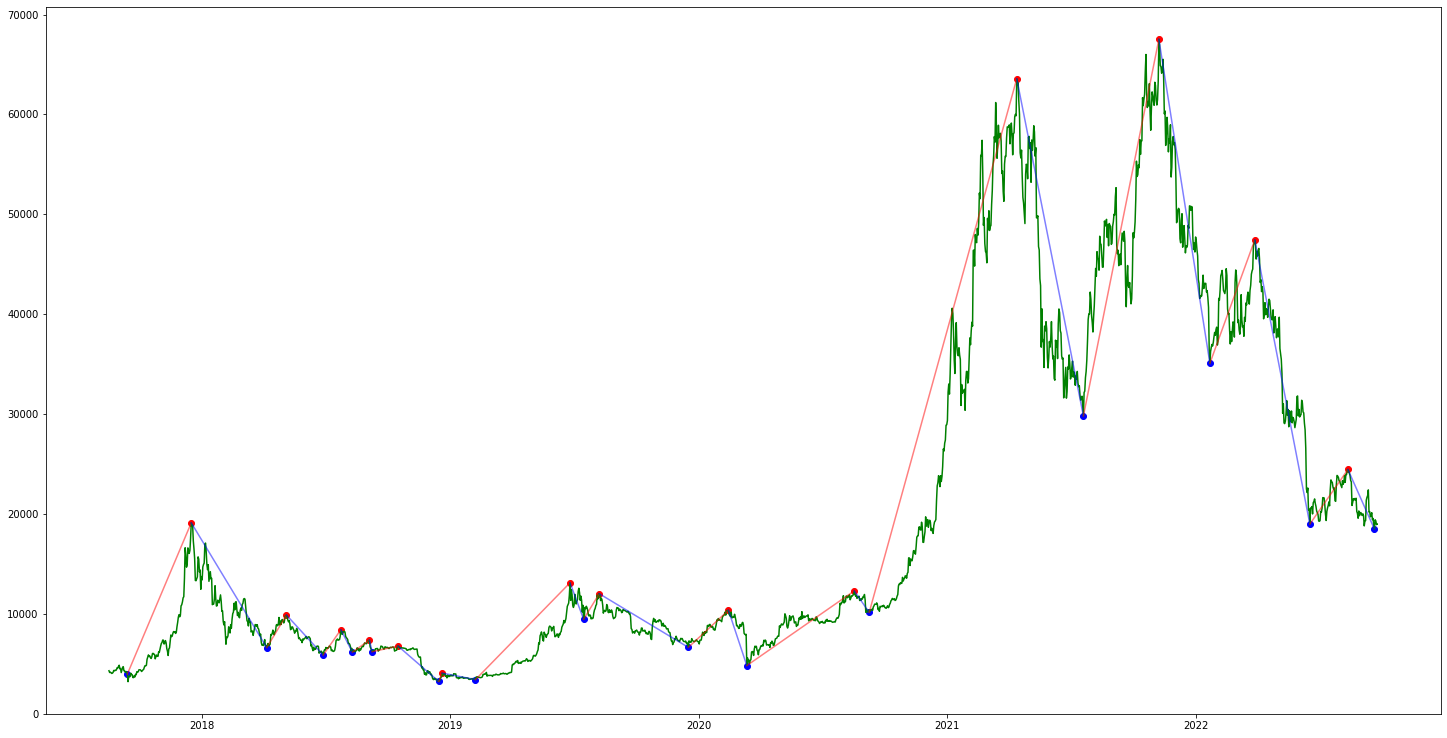
위와 같이 라벨링된 그림과 df에 라벨링된 데이터가 저장되게 된다. 그러면 라벨링된 데이터를 가지고 학습을 시켜보겠습니다.
모델 학습 및 검증
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
|
X,Y = df.drop(['label'],axis = 1),df['label']
x_train = X.iloc[:-500]
y_train = Y.iloc[:-500]
x_test = X.iloc[-500:]
y_test = Y.iloc[-500:]
# 객체 생성
model = XGBClassifier()
xgb_model = model.fit(x_train, y_train)
# 예측하기
y_pre = xgb_model.predict(x_test)
print(classification_report(y_pre,y_test))
fig = plt.figure(figsize=(16,9))
for i in range(len(y_pre)):
if y_pre[i] == 0:
fig = plt.scatter(x_test.index[i],x_test.iloc[i]['close'],color='r')
pass
elif y_pre[i] == 1:
fig = plt.scatter(x_test.index[i],x_test.iloc[i]['close'],color='g')
pass
elif y_pre[i] == 2:
fig = plt.scatter(x_test.index[i],x_test.iloc[i]['close'],color='y')
plt.plot(x_test['close'])
|
cs |
학습모델은 xgboost모델을 사용하였고 파라미터는 디폴트로 주었습니다. 결과 그래프를 보면 다음과 같습니다.
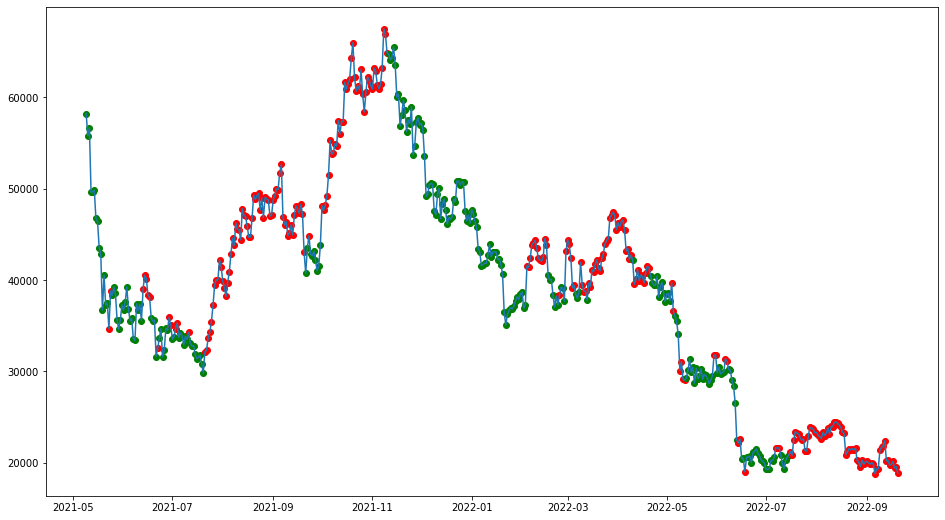
빨간색이 상승추세를 예측한 것이고 초록색이 하락추세를 예측한 라벨입니다. 정확도는 70퍼센트정도 나왔습니다. 금융데이터를 예측하면서 나름 의미있는 결과라고 생각합니다. 이 모델을 가지고 실제 투자는 어렵겠지만 어느정도 참고는 가능하다고 생각합니다. 아직 모델의 초기 단계이기 때문에 모델을 개선한다면 더 좋은 결과가 나올수 있다고 생각합니다.
'파이썬 머신러닝' 카테고리의 다른 글
| [ML/AI][Bitcoin Data Analysis And RNN Model Prediction] (0) | 2022.09.20 |
|---|---|
| [ML/AI][SimpleRNN with Keras] (2) | 2022.09.20 |
| [머신러닝][교차검증, 파라미터 튜닝] (0) | 2021.05.02 |
| [머신러닝][kaggle 실습- 보험 비용 예측하기] (2) | 2021.02.23 |
| [머신러닝][Deep learning을 이용한 XOR문제해결] (0) | 2021.02.14 |